NATのはなし
NAT(Network Address Translation)は幸か不幸か、いまのインターネットには不可欠になってしまった技術です。今回はこのNATのはなしですが、NATの話に入る前に「そもそも元のIPネットワークとはどういうものだったのか」という解説も行います。
目次
あるべきIPルーティング
IPプロトコルの最初の仕様RFC791がリリースされたのは1981年9月のことでした。最初のインターネットでは4桁表記の32bitアドレスで(※註1)、ネットワーク規模はクラスA・B・Cの3段階に分けられていました。
(※註1) 後に「IPv4アドレス」と呼ばれることになります。これは実験的なIPv1~IPv3仕様に続く4番目の仕様という意味で、「32bit=8bitで4桁だからv4」という俗説は正しくありません。
クラスA:1.x.x.x~127.x.x.x
クラスB:128.0.x.x~191.255.x.x
クラスC:192.0.0.x~223.255.255.x
IPネットワークでは、1つの「ローカルネットワーク」内ではアドレス上位(ネットワークアドレス、後にプレフィックスと呼ばれる)を共有し、上位の異なるアドレスは「外側にある」と認識される仕組みになっていました。例えばローカルネットワーク192.168.0.x内のノードには192.168.0.0~192.168.0.255まで256台のホストが収容されて直接通信でき、上位桁が192.168.0.xでないアドレスは「そのネットワークの外側」に接続されているはずで、ネットワーク内外の中継を行う「ルーター」あるいは「ゲートウェイ」へ送信される仕組みになっていました。「どこ行きのパケットを誰に投げるべきか」をルーティングテーブルと呼び、それがわからないときに「とりあえず此処に投げる」先をデフォルトルーターあるいはデフォルトゲートウェイと呼んでいます。
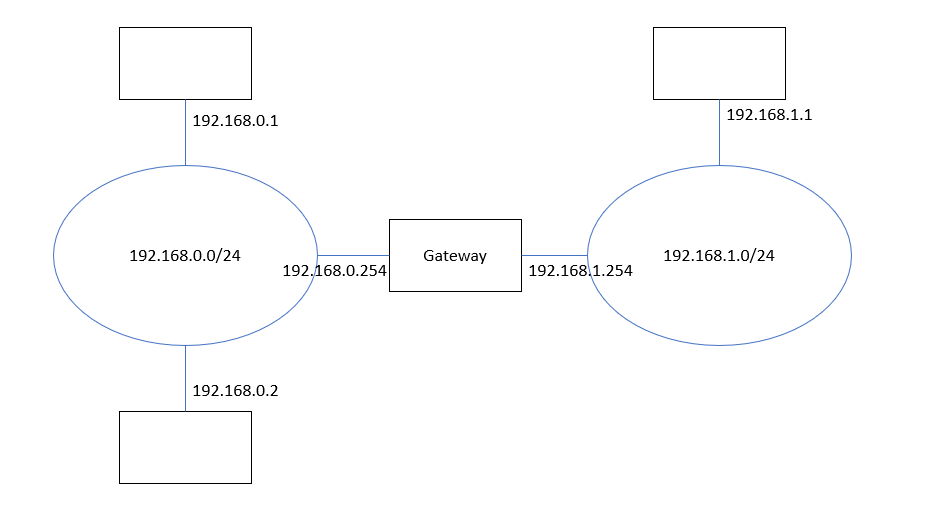
(図1) IPネットワークの例
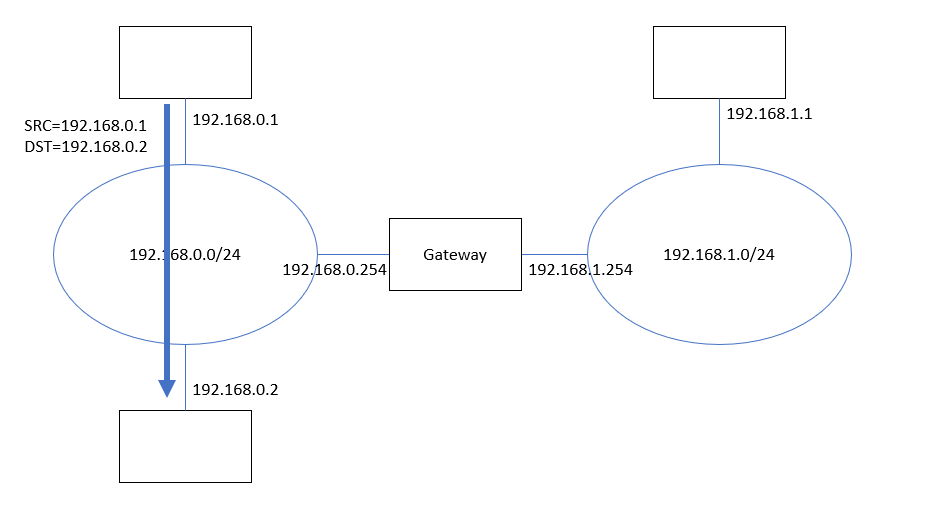
(図2) ローカルネットワーク(192.168.0.x)内での直接通信経路
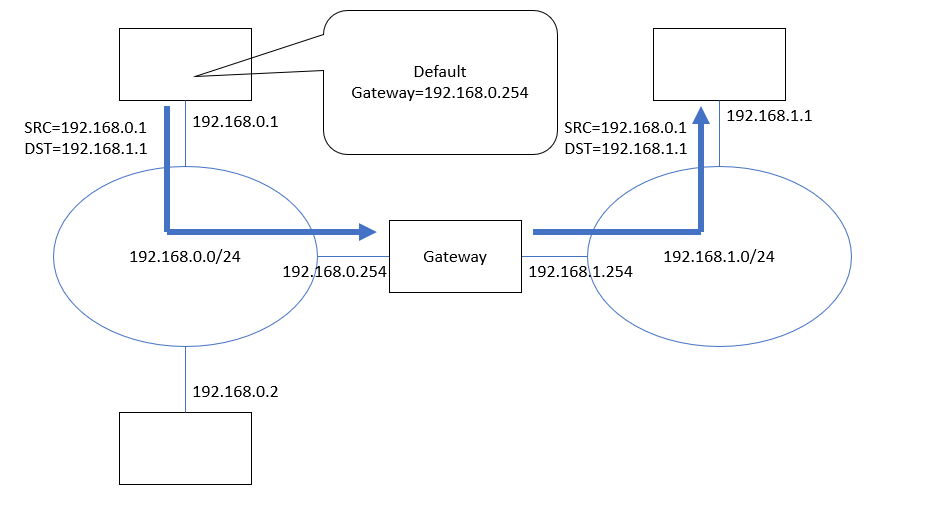
(図3) 192.168.0.xから192.168.1.xへ「出てゆく」通信経路
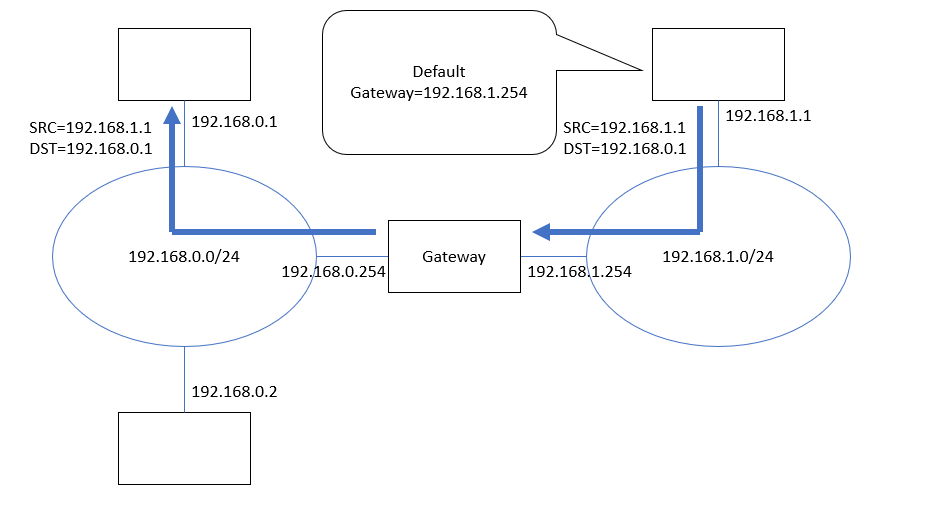
(図4) 192.168.1.xから192.168.0.xへ「戻ってくる」通信経路
RFC791の時点では、まだ1対多の一斉通信(ブロードキャスト)は定義されていません。255.255.255.255がブロードキャストとして定義されたのはRFC919(1984/10)です。また、all-zero(*.0)やall-one(*.255)のホストアドレスを特別扱いもしていません。これを定義したのはRFC943(1985/4)で、all-zeroは「自分自身」、all-oneは「全ホスト」を意味する"Special Address"として定義されました(※註2)。
(※註2) RFC943原文では「the address zero is to be interpreted as meaning "this", as in "this network". The address of all ones are to be interpreted as meaning "all", as in "all hosts」となっています。
IPアドレスとルーティング規則の進化(複雑化)
次の大きな仕様追加はRFC950(1985/8)の「サブネットマスク」の追加でした。IPネットワークが広まるにつれ、アドレス空間をより細分化して使いたい(※註3)という要求が出てきたことに応えたものです。
(※註3) 今では想像できませんが、1980年代にはIP加入を申請するとClass Cのアドレスくらい割と気安く割り当てて貰え、ちょっと大きな組織ならClass Bを貰うこともありました。
例えば192.168.0.xを4分割する場合には、subnet mask=255.255.255.192を設定すると、
192.168.0.0~192.168.0.63 (subnet 0)
192.168.0.64~192.168.0.127 (subnet 1)
192.168.0.128~192.168.0.191 (subnet 2)
192.168.0.192~192.168.0.255 (subnet 3)
を別のネットワークとして扱える、というものです。ただしRFC919で「ホストアドレスのall-zeroとall-oneは特別扱い」と定義されているため(※註4)、実際に割り当て可能なホスト数は64ではなく62になります。さらにRFC950では「the values of all zeros and all ones in the subnet field should not be assigned to actual (physical) subnets」と定義しており、2^n分割したネットワークのうち2つ(上の例ではsubnet 0と3)は使えないことになってしまいました。
(※註4) RFC919原文では「If the use of "all ones" in a field of an IP address means "broadcast", using "all zeros" could be viewed as meaning "unspecified"」となっています。
CIDRの登場
次の大きな仕様変更はだいぶ時代を下り、1993/9のRFC1517~1519の3部作「CIDR(Classless Internet Domain Routing)」になります。90年代の「.COMブーム」によってインターネットは急拡大し、32bit IPv4アドレスの枯渇が現実の脅威として認識されるようになりました。この脅威に対応すべくアドレス幅を拡大した次世代IP(IPng、後のIPv6)の規格検討は1993年暮れから始まりますが(RFC1550)、現行のIPv4インターネットのアドレス有効利用率を上げて延命するための仕様拡張がCIDRでした。
CIDRではこれまでの「クラスA・B・Cの分割+オプションでサブネットマスクによる再分割」という考え方から「サブネットマスクをネットワーク分割の基本単位とし、クラスA・B・Cはサブネットマスクが定義されていなかった場合の特例とする」という発想の転換が行われました。これによって例えば192.168.0.0/255.255.0.0のように、もともとクラスCだったアドレス空間をまとめてクラスB相当として使うこともできるようになりました。
なお現代では"192.0.0.0/255.0.0.0"ではなく"192.0.0.0/8"のように、サブネットマスクの連続1ビット長を書く(Prefix length表記)のほうが一般的になっていますが、この仕様はRFC1517~1519にはまだ定義されていません。これが最初に登場するのはおそらくRFC1812(1995/6)で
More up to date protocols do not refer to a subnet mask, but to a prefix length; the prefix" portion of an address is that which would be selected by a subnet mask whose most significant bits are all ones and the rest are zeroes.
という既述がありますが、まだ/8のような表記の具体例は示されていません。/prefixの具体表記が登場するのはおそらくRFC1860(1995/10)が最初です。
さて、上で述べた「All zeroとAll oneのサブネットは使えない」というRFC950の定義は、RFC1812において「サブネットの特別扱いは有名無実なので廃止すべきである」と提案されました。
DISCUSSION
Previous versions of this document also noted that subnet numbers
must be neither 0 nor -1, and must be at least two bits in length.
In a CIDR world, the subnet number is clearly an extension of the
network prefix and cannot be interpreted without the remainder of
the prefix. This restriction of subnet numbers is therefore
meaningless in view of CIDR and may be safely ignored.
とりわけAll oneサブネットを「全サブネットへの一斉送信ブロードキャスト」として扱うのは5.3.5.3で「壊れた仕様(broken)」「ゴミ箱行き(relegated to the dustbin)」という、今のRFCでは見なくなったカジュアルな表現で強く廃止が推奨されています。RFC1860ではまだAll-zeroとAll-oneサブネットを除外していましたが、2ヶ月後に改定(※註5)されたRFC1878(1995/12)では
Please note that all-zeros and all-ones subnets are included in Tables 1-1 and 1-2 per the current, standards- based practice for using all definable subnets [4].
として、RFC1812の推奨を受けて特別扱いをやめています。
(※註5) この時期のRFCの朝令暮改ぶりは凄まじいですね。.COMブームによるインターネット急拡大とIPアドレスの凄まじい消費量増大にIETF/IANAが慌てている様子が伝わってくるようです。
かくして紆余曲折を経ながら「All-zero, All-oneサブネットの特別扱い」は廃止されたのですが、ホストアドレスのAll-zero, All-oneの特別扱いは残りました(※註6)。ここに例外条件が設定されるのがRFC3021(2000/12)です。「ホストアドレス2つしか含めない(0と1しか無い)/31のプレフィックス設定においては0と1の特別扱いをやめ、ホストアドレスとして認識すべし」というものです。これは個人向けインターネットサービスが広がってプロバイダと加入者が1:1のアドレスで接続されるケースが多くなり、「ホスト数2台きりのサブネット」への需要が高まり、従来は「使えないと」されていたプレフィックス/31を有効活用しようとしたものだと思います。
(※註6) なお、「All-oneアドレスはサブネット内ブロードキャストとして扱う」は多くの実装で踏襲されていますが、All-zeroアドレスの扱いは実装によって異なります。Linuxの場合、192.168.0.0/24のようなアドレスをip address addで付けることもできますし、そこに対してpingなどで通信することも可能です。ただしこれは「Linuxの実装がそうなっている」というだけの話で、All-zeroアドレスがインターネットを通じて通信できることは保証されません。
NATの登場
さて今回の本題、NAT(Network Address Translation)の概念はRFC1631(1994/5)に提唱されました。NATは要するに「内線番号」みたいなもので、ルーターから内側には「その中だけで通用する」ローカルアドレスを使い、ルーターから外に出るときだけ正規のアドレスを「借りて」使うというものです。RFC1631では正規のルーターと区別するため、ローカル⇔グローバルのアドレス変換を伴うルーターを「Stub Router」と呼んでいます。
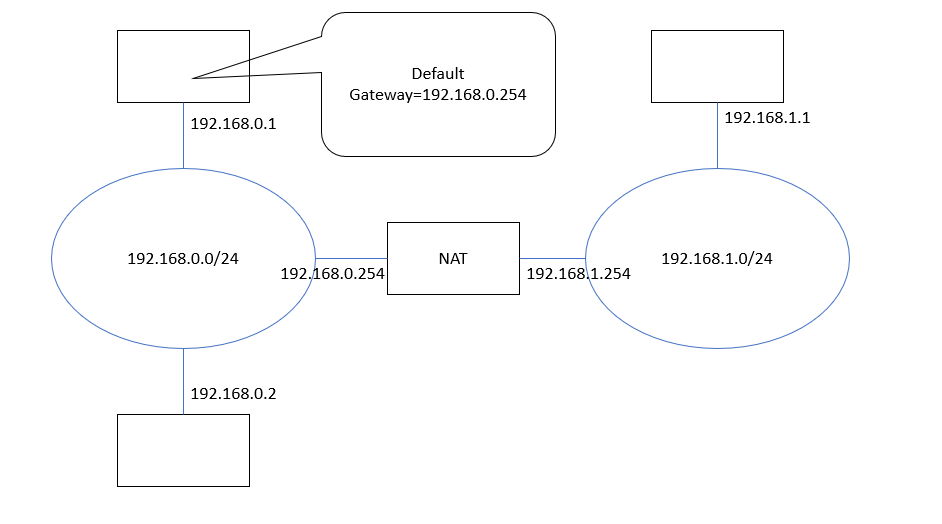
(図5) NATネットワークの例、片側(192.168.0.x)にしかゲートウェイは設定されない。
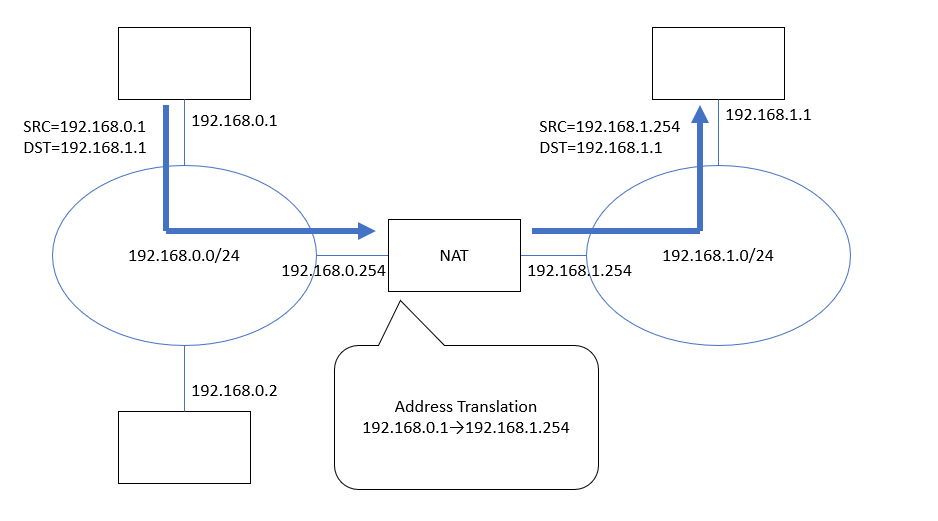
(図6) 192.168.0.xから192.168.1.xに「出てゆく」通信経路、NATで192.168.0.1→192.168.1.254に変換される。
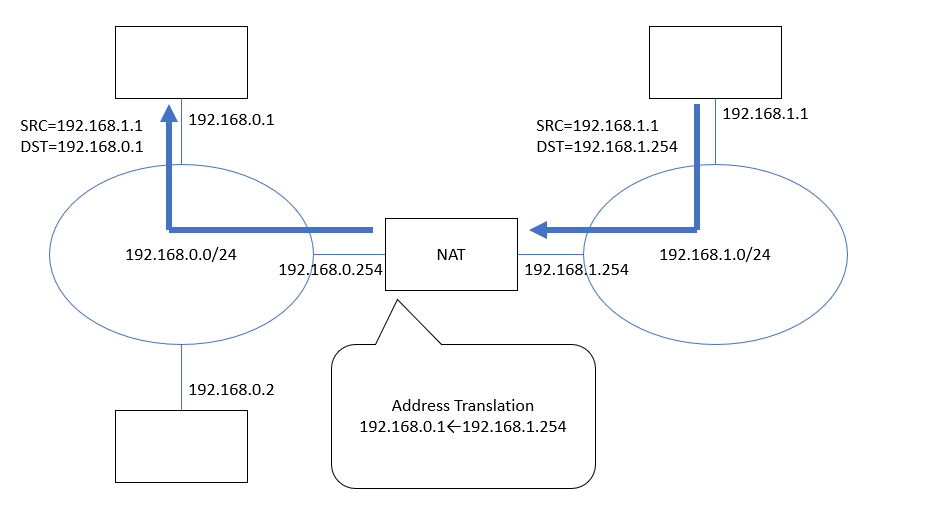
(図7) 192.168.1.xから192.168.0.xに「戻ってくる」通信経路、NATで192.168.1.254→192.168.0.1に変換される。
ローカルアドレスとしては以前から192.168.0.x/24などが慣例的に使われていましたが、公式に「この範囲をローカルアドレスとする」と定められたのはRFC1631の直前のRFC1597(1994/3)でした。RFC1597では下記の範囲がローカルアドレスに割り当てられています(※註6)。
10.0.0.0~10.255.255.255 (10/8 prefix)
172.16.0.0~172.31.255.255 (172.16/12 prefix)
192.168.0.0~192.168.255.255 (192.168/16 prefix)
(※註6) このあとでもう1つ、RFC3927(2005/5)で169.254.0.0/16がローカルアドレスとして追加されました。これはZeroconfと呼ばれたIPネットワーク設定自動化の試みの一環で、DHCPサーバが存在しないとか故障して止まったネットワークではIPアドレスが与えられず、アドレスが無いから一切の通信ができなくなる問題に対処しようとしたものでした。169.254.*.*のホストアドレスは疑似乱数によって付けられるとされており、これを固定アドレスとしてマニュアル設定したりDHCPサーバのリースに含めることは原則として禁止されています。
RFC1631で提唱されたNATはまだ1:1のアドレス差し替えだけで、複数のローカルノードが同時に外部とアクセスしたときのアドレス多重化については考えられていませんでした。これを含んだ仕様がRFC3022(2001/1)になります。
RFC3022では「TCP/UDP Port Translation」という概念が導入されました。ローカルからグローバルへ出てゆくときに、アドレスだけでなくポート番号も差し替えるものです。これによって複数のローカルノードが同時に外部にアクセスしたときも、差し替えるポート番号を違えることによってアドレスを「水増し」できるようになりました。RFC3022ではIPレベルの(RFC1631相当の)NAT動作と区別するためNetwork Address Port Translation (NAPT)という用語を定義していましたが、この用語はあまり定着しませんでした。
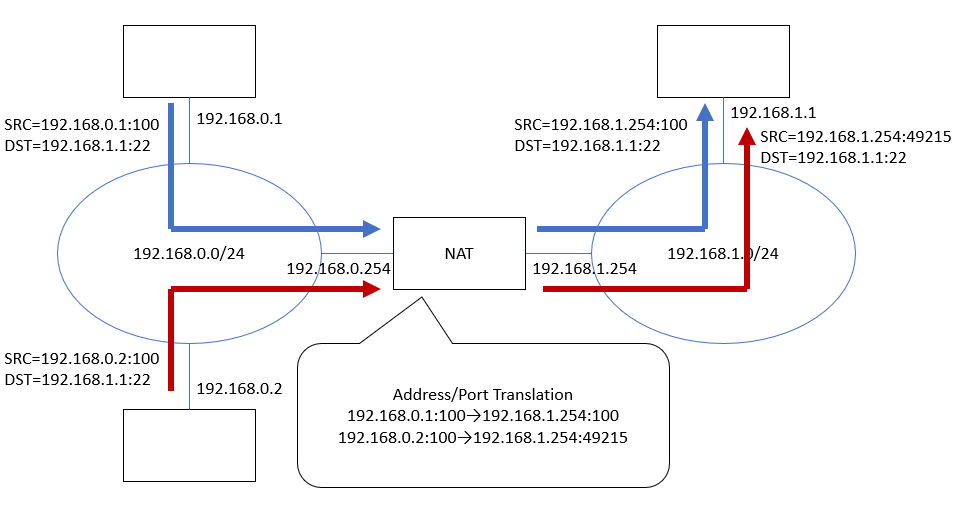
(図8) 192.168.0.xから192.168.1.xに「出てゆく」通信経路。NATで192.168.0.1→192.168.1.254に変換される。192.168.0.2→192.168.1.254は変換後のアドレス/ポートが既に使用済みの192.168.1.254:100と同じになってしまうため、元のポート番号100を適当な空き番号(49215)に差し替えている。
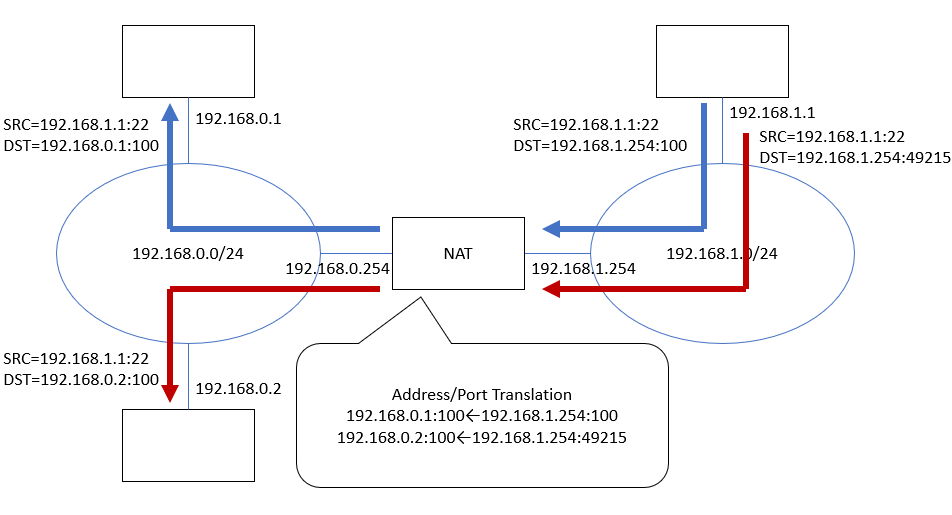
(図9) 192.168.1.xから192.168.0.xに「戻ってくる」通信経路。NATの内側で差し替えるべきアドレスは、宛先ポート番号(100=192.168.0.1, 49215=192.168.0.2)を元に判断している。
幸か不幸か21世紀に入ってもIPv6の普及は遅々として進まず、その一方でDSLやFTTHによる常時接続(ブロードバンド)とWi-Fiによる複数子機接続が当たり前になってゆき、NAT(NAPT)は「あって当たり前、動いて当たり前」の存在になってゆき、やがて「NAT」とすらも呼ばれず単に「ルーター」と呼ばれることが多くなりました。
実験
まずは古典的なIPルーティングの実験を行ってみます。実験にはノートPC 1台とデスクトップPC 1台(どちらもUbuntu 20.04)そしてRaspberry Pi4 (Kernel 5.10.63)を使いました。ネットワーク設定の変更にはroot権限が必要なので、3台とも全てsudo suでrootユーザーになっているものとします。
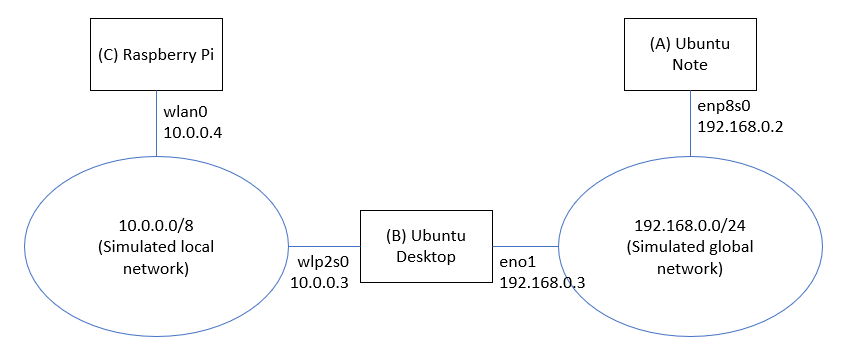
(図10) 実験ネットワークの構成
(A) Note Ubuntu 20.04
enp8s0 192.168.0.2/24
(B) Desktop Ubuntu 20.04
eno1 192.168.0.3/24
wlp2s0 10.0.0.3/8
(C) Raspberry Pi4
wlan0 10.0.0.4/8
まず、今どきのLinuxはネットワークの切断/接続を監視してアドレスの自動取得を試みるネットワークマネージャーが動いているので、これを止めます。Raspberry PiではAutoIP(169.254.x.x)の割り当てをavahi-daemonが行っているので、これも止めます。
Ubuntuの場合:
# service network-manager stop
Raspberry Piの場合:
# service networking stop
# systemctrl stop avahi-daemon
(B)-(C)間は無線LANで接続するので、hostapdとwpa_supplicantを動かしてAP-STAの関係を作っていますが、IPルーティングには直接関係ないので詳しくは触れません。(A) (B) (C)それぞれのノードで、インターフェース毎にIPアドレスを割り振ります。古典的には"ifconfig <デバイス名> <IPアドレス> netmask <サブネットマスク>"ですが、今のLinuxではip addressコマンドを使うことが推奨されています。
(A)
# ip address add 192.168.0.2/24 dev enp8s0
(B)
# ip address add 192.168.0.3/24 dev eno1
# ip address add 10.0.0.3/8 dev wlp2s0
(C)
# ip address add 10.0.0.4/8 dev wlan0
(B) のノードで「ifconfig」および「route -n」を実行すると、こんな風に見えているはずです。(-nは「IPアドレスの名前解決を行わない」を意味します)。
$ ifconfig
eno1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.3 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::5a08:30af:eb7:7c67 prefixlen 64 scopeid 0x20<link>
ether c0:3f:d5:60:cc:ea txqueuelen 1000 (Ethernet)
RX packets 188 bytes 31335 (31.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 208 bytes 34854 (34.8 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
device interrupt 20 memory 0xf7d00000-f7d20000
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 3631 bytes 223659 (223.6 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3631 bytes 223659 (223.6 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlp2s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.3 netmask 255.0.0.0 broadcast 0.0.0.0
inet6 fe80::8625:3fff:fe15:6151 prefixlen 64 scopeid 0x20<link>
ether 84:25:3f:15:61:51 txqueuelen 1000 (Ethernet)
RX packets 55 bytes 9453 (9.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 98 bytes 16559 (16.5 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 wlp2s0
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eno1
この状態で(A)-(B)、(B)-(C)は通信できるはずです。でも(A)-(C)は通信できません。(A)-(B)でもping 192.168.0.3は通りますが、ping 10.0.0.3と打つと
# ping 10.0.0.3
ping: connect: Network is unreachable
になるはずです。一方192.168.0.xの存在しないアドレス、例えばping 192.168.0.99を打つと
PING 192.168.0.99 (192.168.0.99) 56(84) bytes of data.
From 192.168.0.2 icmp_seq=1 Destination Host Unreachable
From 192.168.0.2 icmp_seq=2 Destination Host Unreachable
From 192.168.0.2 icmp_seq=3 Destination Host Unreachable
のようになります。「サブネットが同じホストであれば直接通信できるはず」なのでローカルネットワーク上に192.168.0.99宛てのARP Requestを発信し、一定時間内にその応答が無ければ"ホスト到達不能"というエラー扱いにしているわけです。
ルートを設定するには"ip route add"コマンドを使います。「10.x.x.x行きのパケットは192.168.0.3を通る」というルート指定は以下のように行います。
# ip route add 10.0.0.0/8 via 192.168.0.3
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 192.168.0.3 255.0.0.0 UG 0 0 0 enp8s0
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 enp8s0
ここでもう一度(A)からping 10.0.0.3を実行すれば応答があるはずです。しかし、(B)を超えて(C)の10.0.0.4とは通信できません。これは(B)がパケットの中継(フォワーディング)を行う設定になっていないからです。
# sysctl net.ipv4.conf.all.forwarding
net.ipv4.conf.all.forwarding = 0
これを1に設定するには次のコマンドを使います。
# sysctl -w net.ipv4.conf.all.forwarding=1
net.ipv4.conf.all.forwarding = 1
多分、これでもうまくゆかないはずです。今どきのLinuxはiptablesというファイヤウォールが入っていて、大抵の場合デフォルトでパケット中継が禁止されています。iptablesコマンドを使ってFORWARDの設定を見てください。
# iptables --list
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy REJECT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
この設定を変更するには次のコマンドを使います。
# iptables --policy FORWARD ACCEPT
これで(A)→(B)→(C)のパスは設定できたはずです。でもまだ(A)⇔(C)間の通信は通りません。(C)に「192.168.0.x行きのルーティング」が設定されていないからです。(C)にルーティングを設定するのは下記のコマンドを使います。
# ip route add 192.168.0.0/24 via 10.0.0.3
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 0.0.0.0 0.0.0.0 U 303 0 0 wlan0
10.0.0.0 192.168.0.3 255.0.0.0 U 0 0 0 wlan0
169.254.0.0 0.0.0.0 255.255.0.0 U 303 0 0 wlan0
192.168.0.0 10.0.0.3 255.255.255.0 UG 0 0 0 wlan0
これで(A)⇔(B)⇔(C)間のパケットが通るようになったはずです。これが「IPの本来あるべきルーティング」です。
NATルーティング(Masquerade)の動作
ではここで、せっかく設定したルーティングを外してみます。
(A)
# ip route del 10.0.0./24 via 192.168.0.3
(C)
# ip route del 192.168.0.0/24 via 10.0.0.3
再び(A)-(B), (B)-(C)しか通信できない状態になります。この状態に戻ったところで、(B)で下記のコマンドを使ってNAT(NAPT)を設定します。
# iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -j MASQUERADE
そして(C)ではデフォルトゲートウェイを(B)の10.0.0.3に設定します。
(C)
# ip route add default via 10.0.0.3
するとあら不思議、(A)のルーティングを設定していないのに(C)から(A)の192.168.0.2へのpingが通るようになります。Wiresharkやtcpdumpでパケットを見てみると、(C)→(B)の間ではSRC=10.0.0.4/DST=192.168.0.2になっているのに、(B)→(A)ではSRC=192.168.0.3/DST=192.168.0.2に差し替わっているのが見えるはずです。先程のIPルーティングと異なり、(B)がアドレスを差し替えているので(A)に届いたときは「同じネットワーク内のアドレス(192.168.0.3)」として見えており、返路はルーティグテーブル/ゲートウェイ設定が無くても直接通信できるわけです。
NATの動作は非対称的で、「(ローカルネットワーク)の中から外向け」にしか動きません。つまり(C)からping 192.168.0.2が通るのに(A)からping 10.0.0.4は通りません。良くも悪くもこの非対称性がNATの特徴で、これはセキュリティ向上に効果があるとされることが多いです。(※註7)
(※註7) ただしNATのファイヤウォールとしての有効性については各論あり、ネットワークの専門家ほどNATを嫌い「NATを破る方法なんて幾らでもある」「NATのセキュリティ性など気休め以下に過ぎない」とする人が多いです。
NATで「外から中を見せる(NAT Traversal) 」にはいくつかの方法があります。「ローカルネットワーク上に置いたサーバ(この例では10.0.0.4)の特定のポートを、NATルータのグローバル側アドレス(この例では192.168.0.3)を経由して接続させる」方法をポート・フォワーディグ(Port Forwarding)と呼びます。例えばRaspberry PiのSSH(TCPポート22)を外から接続可能にする設定は、(B)で
# iptables -t nat -A PREROUTING -i eno1 -p tcp --dport 22 -j DNAT --to-destination 10.0.0.4
になります。この状態で(A)から
# ssh pi@192.168.0.3
を実行すれば、(B)のUbuntu Linuxではなく(C)のRaspberry Piに接続するはずです。
# iptables -t nat -A PREROUTING -i eno1 -p tcp --dport 8022 -j DNAT --to-destination 10.0.0.4:22
のような設定にすれば「192.168.0.3のポート8022を10.0.0.4のポート22に接続する」という設定も可能になります。
IPv6とNAT
NATはもともと、90年代インターネットの急激な普及で枯渇の危機に瀕したIPv4を延命するための「場つなぎ」「必要悪」として発明されたもので、アドレス枯渇への本格的な対策はNATとほぼ同時期に制定が開始されたIPng(IPv6)のはずでした。しかし「NATのあるインターネット」があまりに普及した結果、「IPv6でもNATを使いたい」という要求が出てくることになりました。
使い切れないほど広い128bitアドレス空間を持つIPv6で「NATを使いたい」という要求は、IETF/IANAに困惑と反発をもって受け取られたようです。そしてNAT over IPv6など認めたくない、だけど無視することによって各社各様の野良仕様がはびこるのも嫌だという葛藤と激論の末に、RFC6296 NPTv6(Network Prefix Translation)という妥協的な仕様が制定されました(2011/6)。これはIPv4 NATと少し違う原理で、ゲートウェイはネットワークプレフィックス部分だけを差し替え、ホスト部分はそのまま右から左・左から右へ流すというものです。
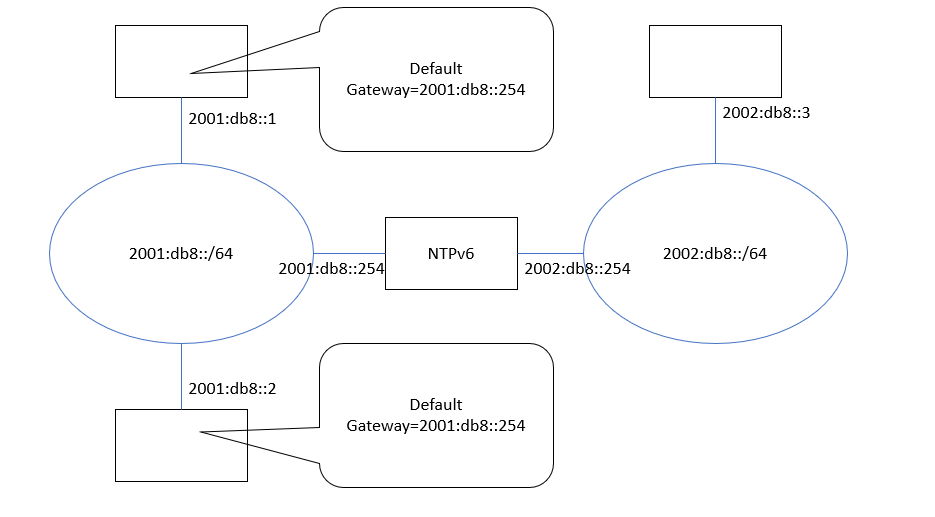
(図11) NPTv6ネットワークの例
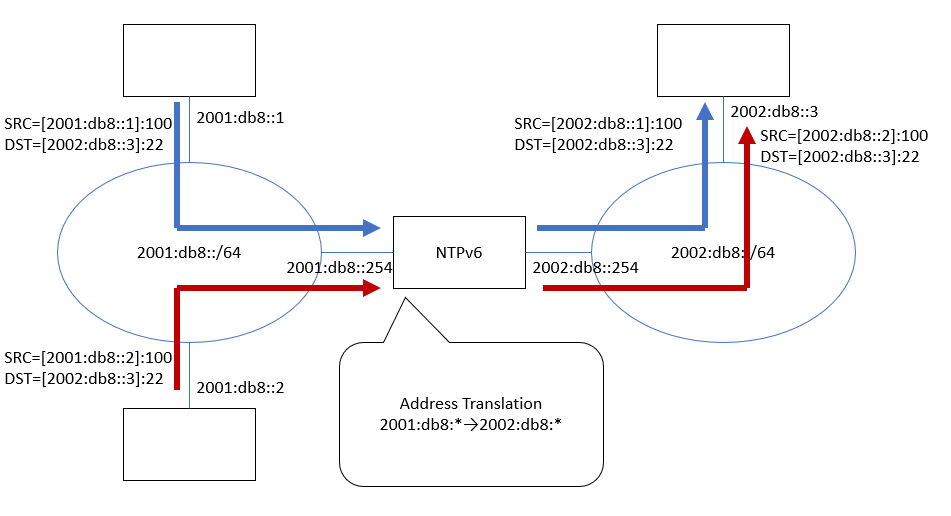
(図12) 2001:db8::から2002:db8::へ「出てゆく」通信経路。ホスト番号(::1および::2)はそのまま、アドレス上位だけが差し替えられる。
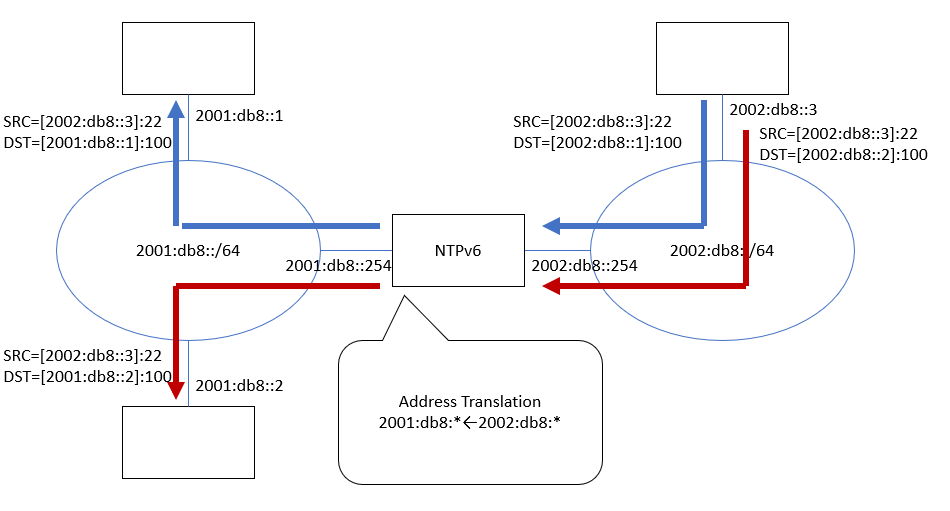
(図13) 2002:db8::から2001:db8::へ「戻ってくる」通信経路。ホスト番号(::1および::2)はそのまま、アドレス上位だけが差し替えられる。NTPv6の右側は2002:db8::1, 2002:db8::2, 2002:db8::254の3つのアドレスを代弁しなければならないことに注意。
IPv4 NATが持っていた「(プロバイダから与えられた)1個のグローバルアドレスを、ポート番号で水増しすることで数百・数千台のノードで共有する」という動作はIETFにとって「悪夢のように醜い」「本来あってはならない仕様」として徹底的に忌み嫌われていたようで、RFC6296にもSection 6で"NPTv6 Translators that comply with this specification MUST NOT perform port mapping"と大文字のMUST NOTで明記しています。
NTPv6ではローカルネットワーク内のノード台数と同じだけのグローバルアドレスをゲートウェイに割り当てる必要がありますが、IPv6の128bitアドレス総数は「地球上の砂粒の推定総数より多い(※註8)」ので、たとえ1ユーザーあたり数千個のアドレスを割り当てても不足することはない...という前提があったようです。
(※註8) 128bitの取り得る値は単純計算だと2^128≒10^38.5です。地球の質量は約60垓トン≒10^27.8gで、1gあたりの砂粒の数を100万個としても10^33.8個となり、IPv6アドレスの方が5桁ほど多い計算になります。実際には128bit全ての組み合わせがアドレスとして使えるわけではありませんが、たとえ利用効率50%としても莫大な数です。
またNPTv6では、ローカルネットワーク内のアドレスも「プレフィックスを差し替えた結果、外のネットワークに同じアドレスが無いこと」を保証されたアドレスを割り当てる必要があります。上の例で言えばローカルネットワーク内のホストに1と2、外のホストに3のアドレスを与えていますが、もし外側に2002:db8::1や2が居ればNPTv6通過後のアドレスと衝突してしまいます。Stateless Autoconfigアドレスなら下位はMACアドレスから生成されるので衝突することは「ないはず」ですが、Stateful Autoconfig(DHCPv6)ではその保証はありません。このアドレス衝突の可能性や回避方法について、RFC6296には明記されていないようです。
そして結局、RFC6296は「野良仕様」が出てくることを止められませんでした。Linuxではカーネル3.9.0(2013/4)/ip6bales 1.4.18以降でIPv6 Masquerading機能が追加され、これはIPv4 NATと同じようにポートマッピングを行うものです。ポートマッピングを行わない(RFC6296仕様の)IPv6 NATを「NPTv6」と呼ぶのに対し、ポートマッピングを伴うIPv6 NATは「NAT66」と俗称されていますが、対応するRFC仕様はありません。また「NAT66」という名前はドラフト時代のRFC6296(draft-mrw-nat66)と似ていますが、「ポートマッピングを行わない」という既述は初版のdraft-mrw-nat66-00から既に明記されており、何処からこの「NAT66」という俗称が出てきたのかよくわかりません。RFC6146(2011/4)という仕様が「IPv6とIPv4の変換装置」として「NAT64」という用語を使っており、ここから「NAT44」や「NAT66」という言葉が出てきたのかもしれません。
Linuxのip6tablesにおけるNAT66の設定はIPv4 NATと殆ど同じで、コマンド名がiptablesからip6tablesになっていること、プレフィックス表記がIPv6仕様になっているくらいです。
(A)
# ip address add 2001:db8::2/64 dev enp8s0
(B)
# ip address add 2001:db8::3/64 dev eno1
# ip address add 2002:db8::3/64 dev wlp2s0
# sysctl -w net.ipv6.conf.all.forwarding=1
# ip6tables --policy FORWARD ACCEPT
# ip6tables -t nat -A POSTROUTING -s 2002:db8::/64 -j MASQUERADE
(C)
# ip address add 2002:db8::4/64 dev wlan0
# ip route add default via 2002:db8::3
こういう設定によって、IPv4 NATとほぼ同じ、「なんだか知らないアドレスは2002:db8::3へ投げる(C)」「2002:db8::*から受信したパケットはソースアドレスを自分のアドレス(2001:db8::3)に変換してフォワードする(B)」という(NAT66の)動作が実現します。
一方、RFC6296に準じたNPTv6の設定は、-j NETMAPで一応設定することはできます。まず-FコマンドでそれまでのNAT設定を消去して...
# ip6tables -t nat -F
「中→外」「外→中」のそれぞれのプレフィックス変換規則を設定します。
# ip6tables -t nat -A POSTROUTING -s 2002:db8::/64 -o eno1 -j NETMAP --to 2001:db8::/64
# ip6tables -t nat -A PREROUTING -s 2001:db8::/64 -i eno1 -j NETMAP --to 2002:db8::/64
この設定によって(C)→(B)→(A)のパケットは通るようになりますが、逆向きの(A)→(B)→(C)はまだ動きません。(C)のアドレス2002:db8::4は(B)を通ったとき2001:db8::4に変換されますが、(A)がこの「知らない」アドレスに対してNeighbor-solicitationをかけても(B)は応答してくれないからです。
これは(B)にIPv6 Neighbor Discovery Proxyを設定することで一応動かすことができます。
# sysctl -w net.ipv6.conf.eno1.proxy_ndp=1
# ip -6 neigh add proxy 2001:db8::4 dev eno1
LinuxはIPv4とIPv6で近隣検索の応答挙動が違い、IPv4では「どのインターフェースから受信したARP Requestでも、自分が持っているアドレスに一致すればそのインターフェースからARP Replyを返す」という挙動がデフォルト(※註9)なのに対して、IPv6は上のような設定で明示的に代理応答を設定する必要があります。そしてip -6 neigh add proxyはアドレス範囲での指定ができないので、ローカルネットワーク側にあるノードのアドレスを1つ1つproxy登録しなければなりません。Masquerading(NAT66)にくらべると妙に不便なのですが、どういう事情でこうなっているのかよくわかりません。
(※註9)「Proxy ARP」という古い仕様が引き継がれています。sysctl net.ipv4.conf.all.arp_ignoreという設定項目で挙動を変えることもできます。
なお、-t nat / -j NETMAPではなく-t mangle / -j SNPT (DNPT)を使っても似たような動きをさせることができ、NetfilterとしてはこちらがNPTv6の「正式な」対応ということになっているようです。
# ip6tables -t mangle -A POSTROUTING -o eno1 -s 2002:db8::/64 -j SNPT --src-pfx 2002:db8::/64 --dst-pfx 2001:db8::/64
# ip6tables -t mangle -A PREROUTING -i eno1 -d 2001:db8::/64 -j DNPT --src-pfx 2001:db8::/64 --dst-pfx 2002:db8::/64
しかし、やっぱりNeighbor Proxyを設定しなければ帰りのパケットは通りません。しかもNETMAPと違ってNPTv6通過後のアドレスはどういう訳か2001:db8::1:x:x:xになるので、proxy設定もそれに対応したアドレスにする必要があります。
# ip -6 neigh add proxy 2001:db8::1:0:0:4 dev eno1
まとめ
1981年から40年以上にもわたるIPv4/IPv6の仕様の変遷と、NATという「必要悪の発明」そしてIETFの抵抗と妥協の流れ、そしてLinuxでNATを設定稼働させる方法について駆け足で解説してみました。
改めて見ると、90年代にIPv4アドレスの分割仕様が次々に追加されていることがわかり、インターネットブームでアドレス割り当てが急増し枯渇の脅威が急速に迫っていた空気が伝わってきます。IPv6仕様制定はそれに対応するため急ピッチで進められたのですが、NATの発明と実用化は期待以上にIPv4を延命させ、それがかえってIPv6普及を遅らせることになったのは皮肉です。
最後に、IP(v4/v6)とNATにまつわる主なRFCを時系列に並べると次のようになります。
RFC791 (Sep 1981) 最初のIP仕様
RFC919 (Oct 1984) 255.255.255.255ブロードキャストの追加
RFC943 (Apr 1985) All-zero, All-oneホストアドレスの特別扱い
RFC950 (Aug 1985) サブネットマスクの追加、All-zero, All-oneサブネットの特別扱い
RFC1517 (Sep 1993) 可変長サブネットCIDR
RFC1550 (Dec 1993) IPngドラフト募集の告知
RFC1597 (Mar 1994) IPv4ローカルアドレスの定義
RFC1631 (May 1994) NATの提唱
RFC1812 (Jun 1995) All-zero, All-oneサブネットの特別扱いの廃止推奨
RFC1860 (Oct 1995) サブネットの/prefix表記
RFC1878 (Dec 1995) All-zero, All-oneサブネット特別扱いの事実上廃止
RFC1884 (Dec 1995) 最初のIPv6仕様
RFC3021 (Dec 2000) IPv4 prefix/31におけるAll-zero, All-oneホストアドレスの例外扱い
RFC3022 (Jan 2001) NAPTの提唱
RFC3879 (Sep 2004) IPv6 Site Local Address(fec0::/10)の廃止宣言
RFC3927 (May 2005) IPv4 Auto Address (169.254.x.x)の定義
RFC5902 (Jul 2010) IPv6 NATに対する懸念と議論について
RFC6146 (Apr 2011) IPv6-IPv4 NAT(NAT64)仕様
RFC6296 (Jun 2011) NPTv6仕様